Improving search engine results with dictionary data
Enhance your
search results
Search engines sometimes choose to include dictionary snippets as a feature of their results pages.
Primarily, this is a way to improve their user’s experience by providing quick, clear answers to language comprehension searches, such as “define dog”, “synonyms for dog”, or “use dog in a sentence”, removing the need to rely on potentially less-accurate or sometimes conflicting organic and paid search results.
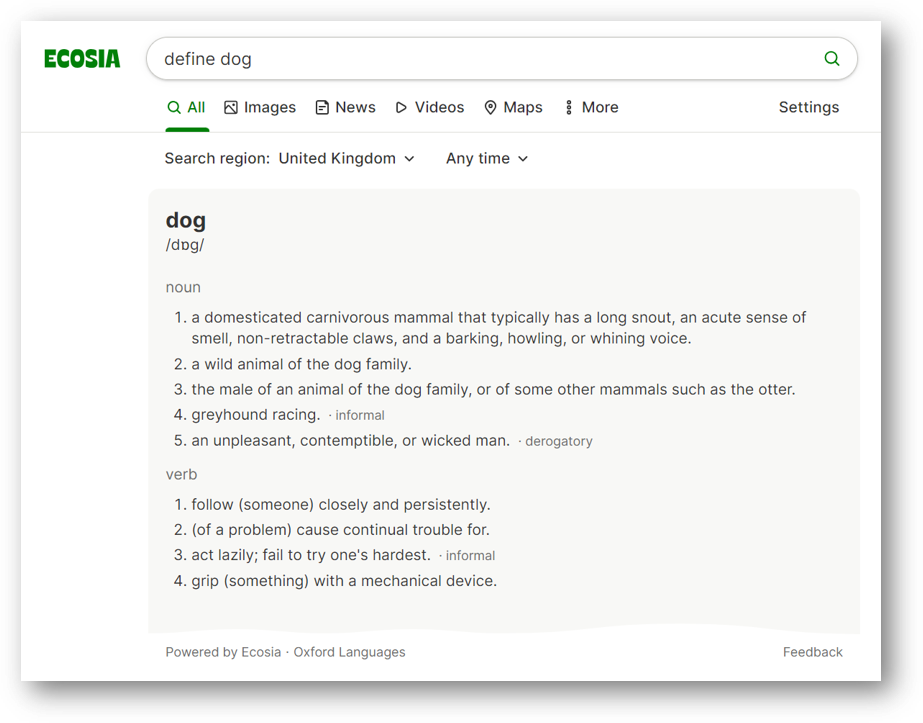
The standardized data models of our machine-readable dictionaries give your dev team a near-seamless experience when ingesting into your pipeline, and we provide comprehensive onboarding notes and support from our Customer Success team as standard.
Our data is human-curated by our team of expert lexicographers, ensuring high levels of accuracy that your users will love. And you can feel confident that your primary dictionary search experience is the product of the meticulous research that goes in to every one of Oxford University Press’s publications.
Companies that
trust our data

![]()


![]()
Our British-English and American-English monolingual dictionary datasets are made up of roughly 60 different data and linguistic features. Here are some of the main features you might need:

Our research has shown that certain features found in our datasets can assist with a range of natural language processing tasks that search engines use, such as word sense disambiguation.
We also offer a range of mono and bi-directional translation datasets to support translation use cases, for both display and machine translation.
Do you have an idea for how our data could be used in your search engine? Let us know below! We partner with some organisations undertaking interesting research.


Our Privacy Policy sets out how Oxford University Press handles your personal information, and your rights to object to your personal information being used for marketing to you or being processed as part of our business activities.