Lexical Datasets for NLP: Pronunciations data

Pronunciation data for
Natural Language Processing
Text-to-speech (TTS) model quality and performance can be improved with Oxford Languages pronunciation data, covering most words and English variations such as American, British, Australian, Indian and World English with curated pronunciation data including IPA transcription pronunciations, audio recording files, and alternative respelling data.
Our data is carefully compiled by our in-house team of language experts as an output of our language research programme, one of the largest in the world.



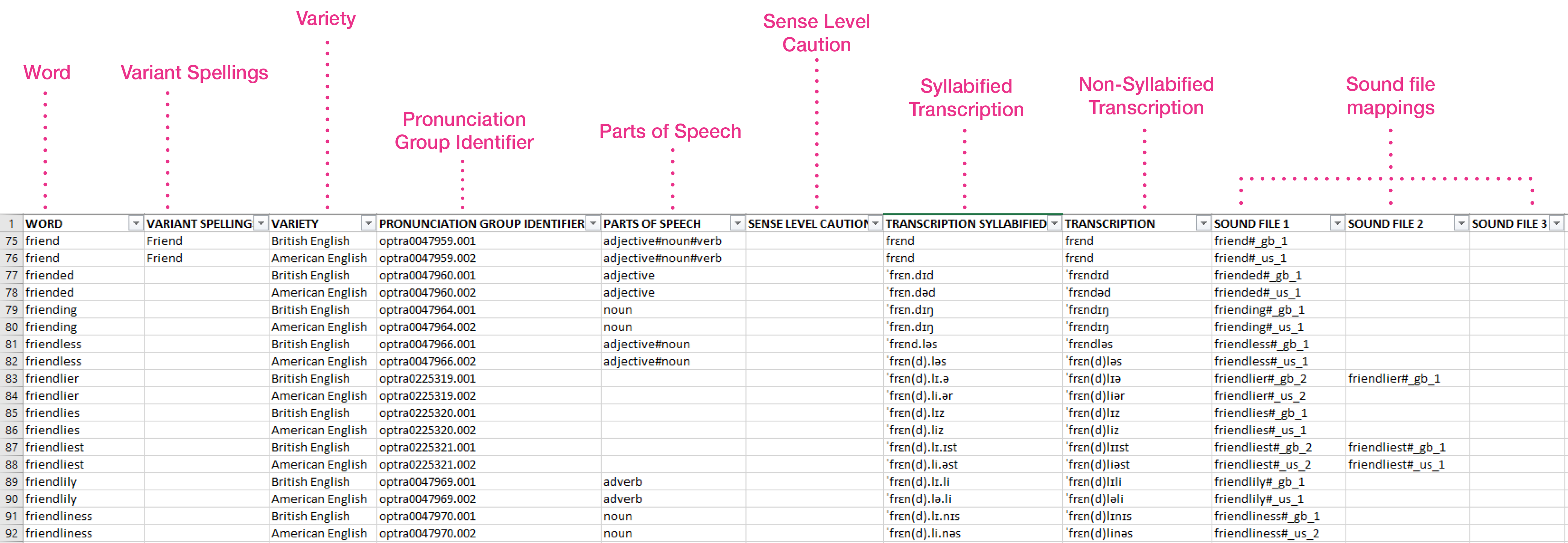
Our pronunciation transcriptions and audio files cover more than 500,000 phonetic transcriptions, including words from different domain-specific vocabulary, acronyms, abbreviations and initialisms.
- Syllabified and non-syllabified IPA (International Phonetic Alphabet) transcriptions for each wordform to give the most natural and accurate pronunciation for speech synthesis use cases
- Variant spellings of each word (# is used as a separator) to enable coverage of pronunciation variations which are used and accepted
- Variety of English, British, American, Australian, Indian and World English to allow for the user experience to be tailored per locale
- Pronunciation group identifier, a unique identifier for each pronunciation group. Pronunciations which have the same identifier are used interchangeably e.g. engross /ɪnˈɡroʊs/ /ɛnˈɡroʊs/
- Parts of speech (# is used as a separator), to aid disambiguation where the correct pronunciation is not clear from the spelling
- Sense level caution which offers a further warning that the pronunciation may vary according to sense (i.e. is not made clear by spelling and given parts of speech)
- Sound file mappings to appropriate high-quality audio files recorded in a controlled environment
The Oxford English Text Respell provides a visual means for interpreting pronunciations, without the need for phonetic or linguistic knowledge.
- Offer 500,000 English pronunciations and delivers complete coverage of English words, including inflections
- Developed for intuitive and accessible use for the non-specialist human reader
- Comprehensively covering both American and British English

Our Privacy Policy sets out how Oxford University Press handles your personal information, and your rights to object to your personal information being used for marketing to you or being processed as part of our business activities.